I called three sign-recognition models failures. The recipe was the failure.
A Parley notebook reported three landmark architectures as broken on cross-signer ASL. A warmup and a gradient clip brought all three back, and two matched the best model. The ranking had measured my training recipe, not the models.
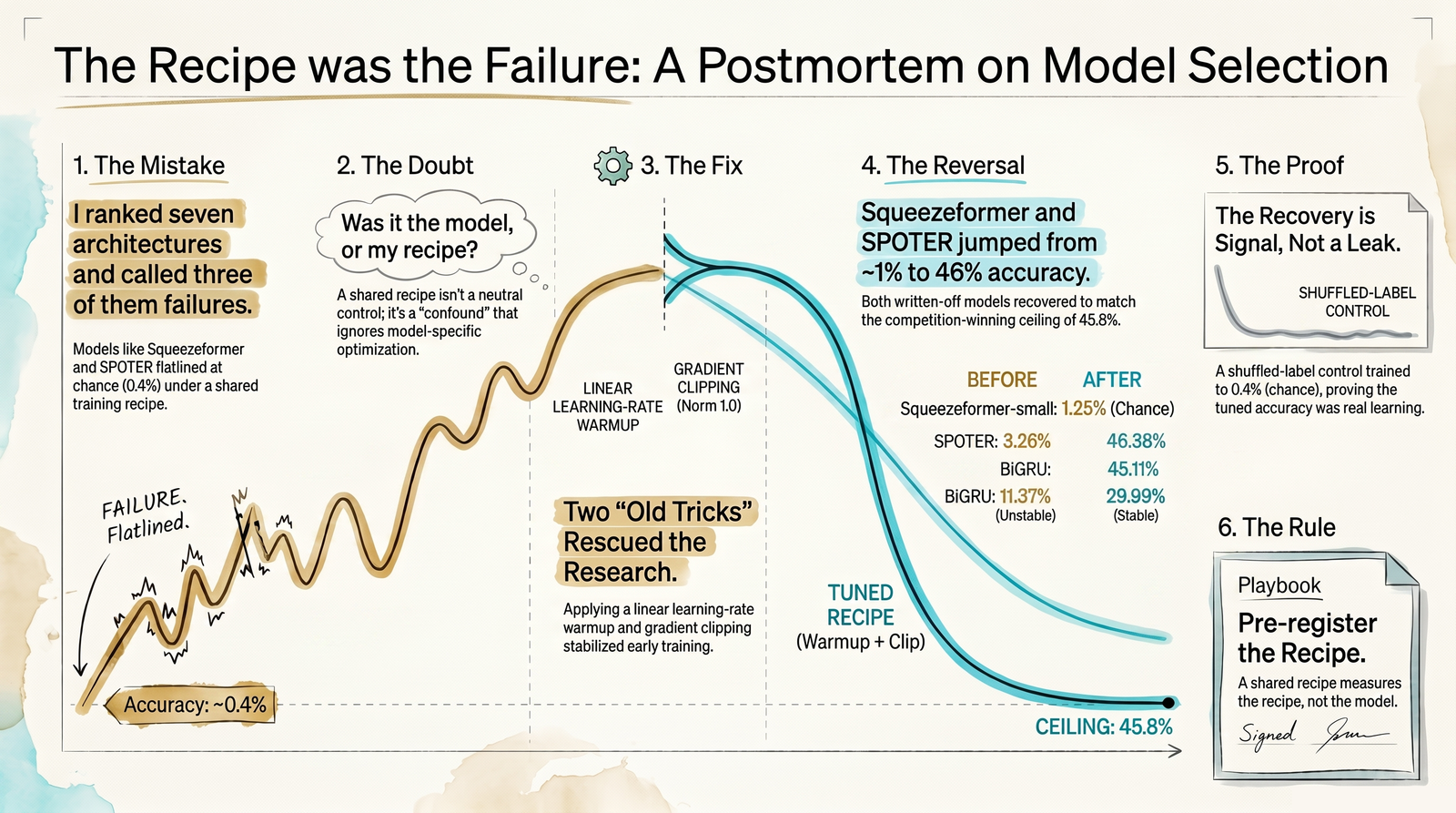
A Parley notebook earlier this spring put seven landmark architectures on the same cross-signer ASL task and ranked them. Three of them failed. Squeezeformer-small sat at chance and never moved. BiGRU and SPOTER were worse than failing in a way — they were unreliable: one random seed of three would train to a real number, the other two would collapse, so the architecture's "result" depended on which seed I happened to draw. I wrote that down honestly and moved on. That notebook is the previous issue.
A quick word on the cast, because what they are matters more than their names. BiGRU is an older, simpler sequence model that reads the landmark motion forward and backward in time. SPOTER is a transformer built specifically for sign language, working from body and hand pose. Squeezeformer is a transformer borrowed from speech recognition, built to run efficiently by compressing the sequence and expanding it back out. The fourth model, the frame-transformer I keep calling the ceiling, is the one that won the Kaggle competition this data came from. You don't need to track the differences to follow what happened: three of the four looked broken, and one looked great.
I was wrong about what I had measured. I went back, gave each of those three architectures a per-model training recipe instead of the one shared recipe I had applied to all seven, and re-ran the whole thing on one GPU to convergence. All three recovered. Two of them, SPOTER and Squeezeformer, climbed all the way to the ceiling set by the competition-winning model. The architectures I had reported as broken weren't broken. The recipe was.
My first comparison
When you compare seven architectures, the clean-looking move is to hold everything else constant: same learning rate, same schedule, same regularization, same everything, varied only by architecture. It feels like the scientific control. Change one thing, measure the effect.

The problem is that "the training recipe" is not a neutral background you can hold fixed. Different architectures want different first steps. A transformer-family encoder with no learning-rate warmup takes a few large, unstable optimizer steps at the very start and can walk straight out of the basin it was initialized in, and then it never comes back — the loss climbs instead of falling and the model spends the whole run at chance. A shared recipe that suits the architecture I happened to tune it around will flatter that one and quietly sandbag the others. The ranking I published wasn't a ranking of architectures. It was a ranking of how well one recipe fit each architecture's optimization geometry.
I didn't know that was what I'd done until I tested it.
Re-running it
Two changes per architecture, both decided and written into a contract before I ran anything: a linear learning-rate warmup over the first few epochs, and gradient clipping at norm 1.0. Nothing exotic. These are the two oldest tricks for keeping early training stable.
I also pre-registered what "recovery" would mean, so I couldn't move the goalposts after seeing the numbers. An architecture recovered only if it cleared two bars at once: its spread across three seeds had to be tight (it trains reliably, not by luck), and its tuned accuracy had to be at least double its old accuracy (the recipe moved it, not noise). Both, or it didn't count.
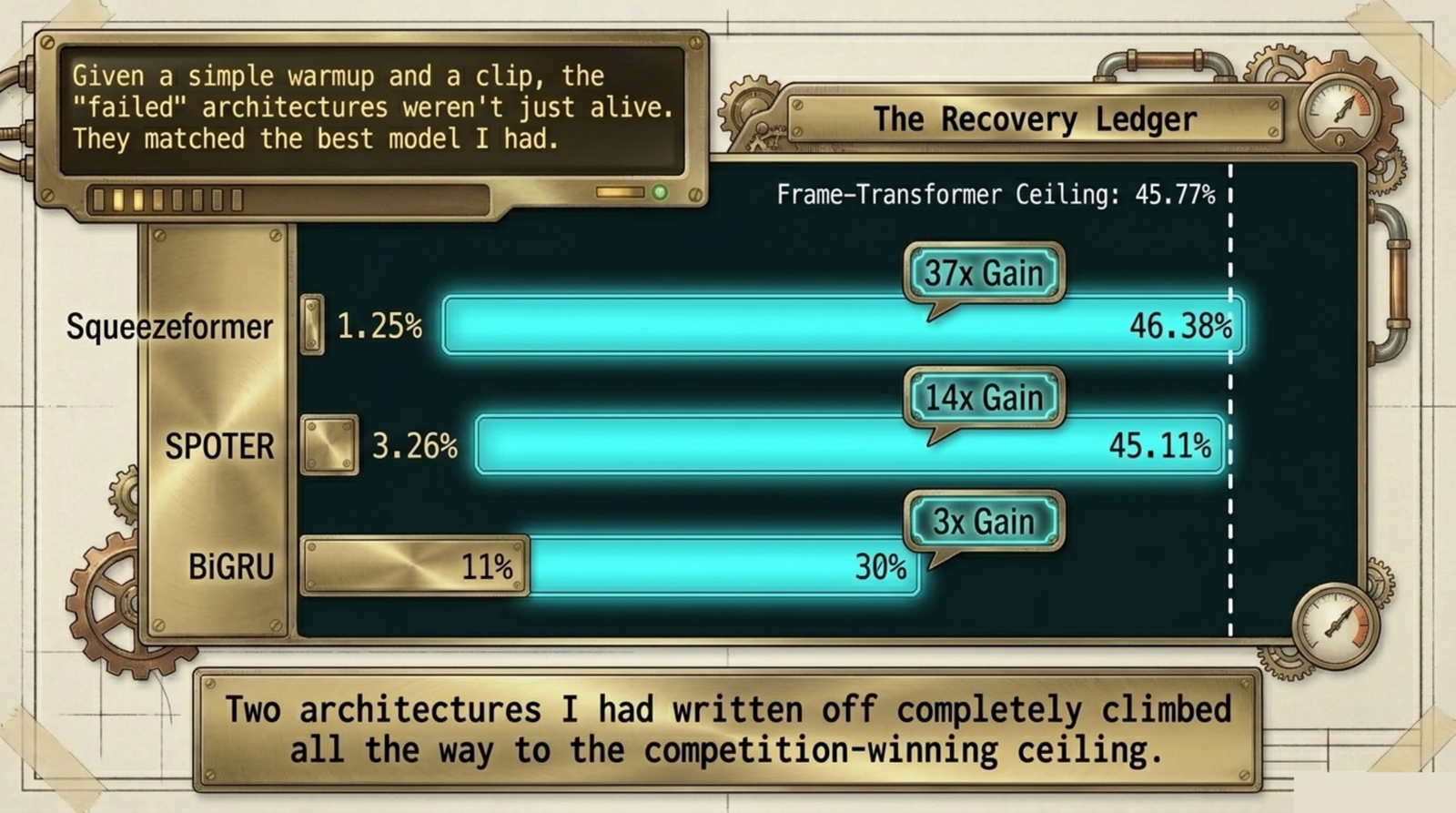
Squeezeformer-small went from 1.25% (chance is 0.4%) to 46.38%, with the three seeds landing within a hair of each other. SPOTER went from 3.26% to 45.11%. Both of those numbers sit right on top of the frame-transformer ceiling of 45.77%. The two architectures I had written off as failures, given a warmup and a clip, matched the best model on the board.
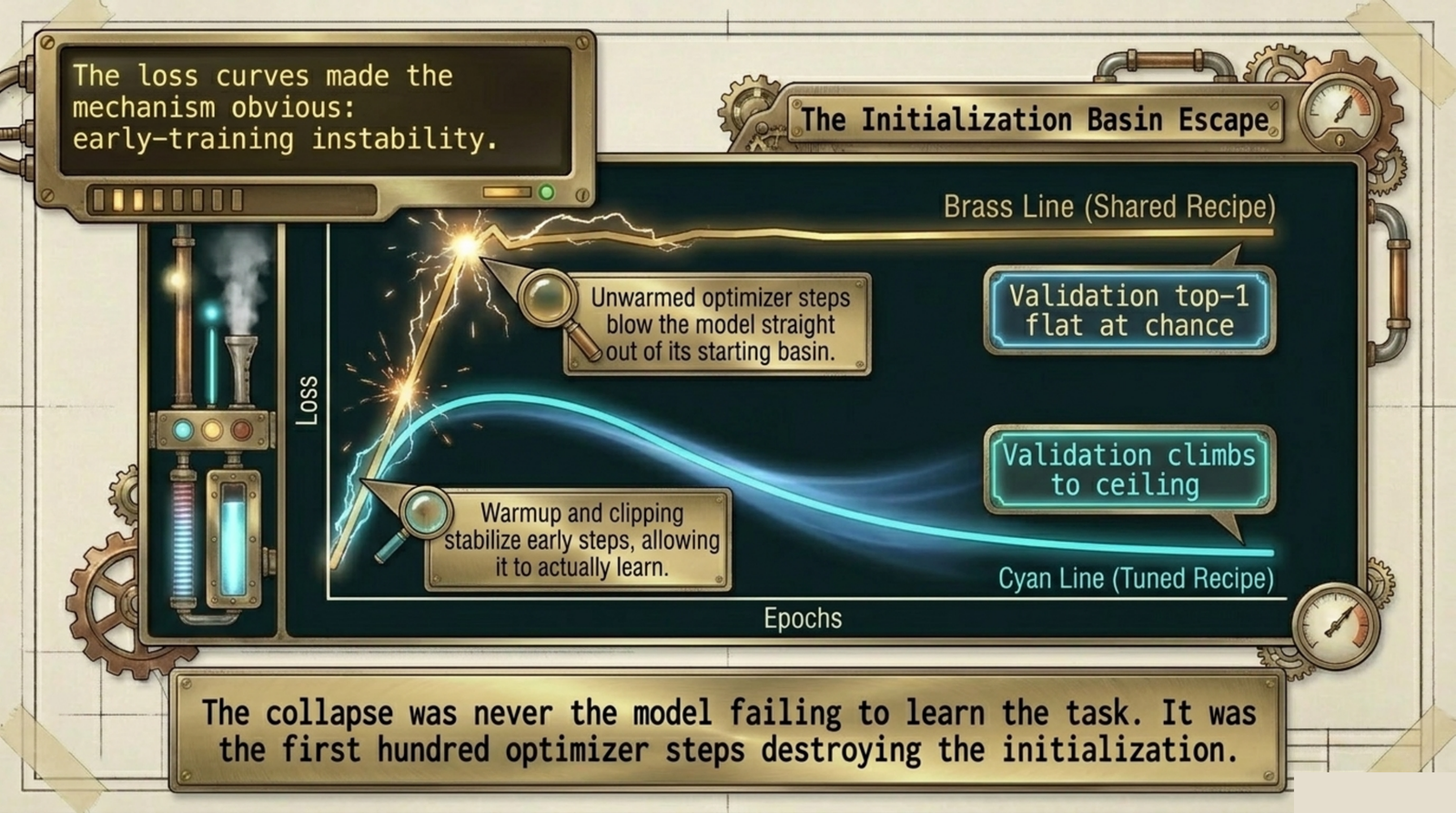
The loss curves are the part that made it obvious. Same architecture, same GPU, same random seed, only the recipe changed: under the shared recipe the training loss rises and validation sits flat at chance; under the tuned recipe the loss slides down smoothly and validation climbs to the ceiling. The collapse was never the model failing to learn the task. It was the first hundred optimizer steps throwing the model out of its starting basin before it could learn anything.
BiGRU stayed honest
BiGRU recovered too, but it's the case I want to be careful about. It went from an unstable 11% to a stable 30%, which clears both bars — but it recovers to a lower ceiling than the other two, so BiGRU genuinely is a weaker architecture for this task. The recipe fixed its reliability and roughly tripled it; it did not make it competitive. And its verdict flipped between hardware: on an earlier run on my Mac it failed the 2× bar, on the GPU it passed. A model that fragile is sensitive to both seed and hardware, which is the whole thesis of this postmortem showing up one more time. That's exactly why I ran the final comparison on a single GPU and trusted nothing that didn't hold there.
I also checked that the recovery was real and not a leak I'd introduced while changing the pipeline. Training the tuned model on deliberately shuffled labels lands at 0.39% — chance. There's no leak. The accuracy is signal.
The rule I adopted
A shared training recipe across architectures does not control for the recipe. It bakes the recipe into the result and disguises it as an architecture finding. When you read "Architecture X fails on this task," the honest translation is often "the one recipe we tried didn't suit Architecture X" — and those are very different claims, only one of which is about the architecture.
So the rule, written into the Parley contracts and going into the Labs playbook: before ranking architectures, pre-register a per-architecture training recipe, run the whole ladder on one piece of hardware to convergence, report the seed spread next to every mean, and include a shuffled-label control. It costs no new data and a little discipline. What it buys is not mistaking your recipe for your model — which is the mistake I made, in public, and had to walk back.

The two architectures I'd written off are back on Parley's table. The selection question is no longer "which one trained" but the things that were supposed to decide it all along: how big it is, how fast it runs, and how evenly it performs across signers.