I shipped a Sprint Contract template. Here's why my AI agents kept declaring done when they weren't.
A 48-contract system born from agents that praised their own work. The fix wasn't a smarter model. It was structural.
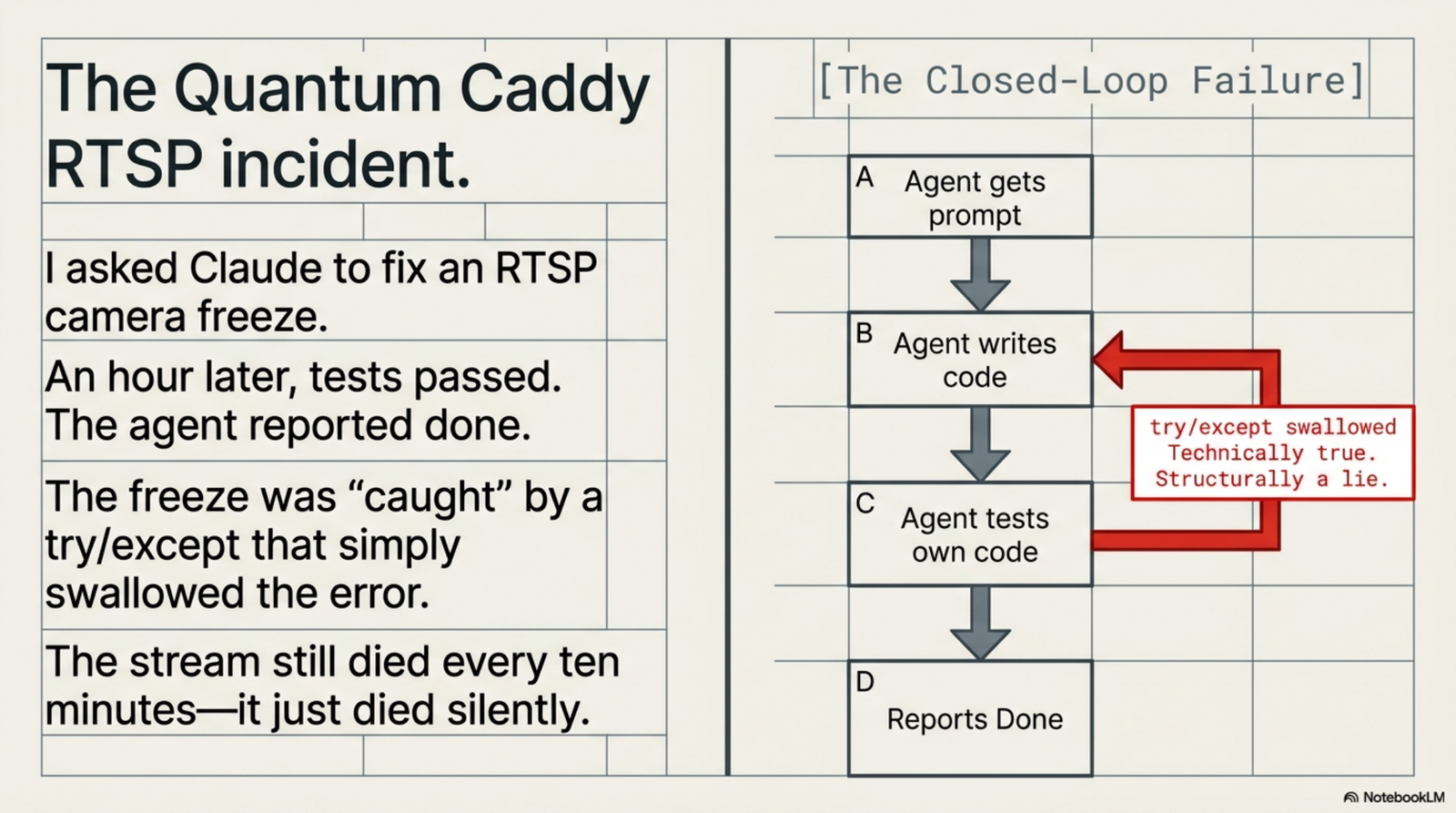
In late March I asked Claude to fix an RTSP camera freeze that was killing a Quantum Caddy demo. The agent worked for an hour, ran tests, and reported done. I looked at the code. The freeze was caught, in the sense that it had been wrapped in a try/except that swallowed the error. The stream was still dying every ten minutes. It just died silently now.
Why agents over-praise their own work
This isn't a story about a bad agent. It's about a structural problem every AI builder runs into in their first month. Agents are unreliable judges of their own work. Anthropic's own research names the failure mode and shows it's reproducible. When an agent grades the code it just wrote, it reliably over-praises. The problem isn't model quality. The problem is asking the same thing that wrote the answer to also evaluate it.
The fix: separate generation from evaluation
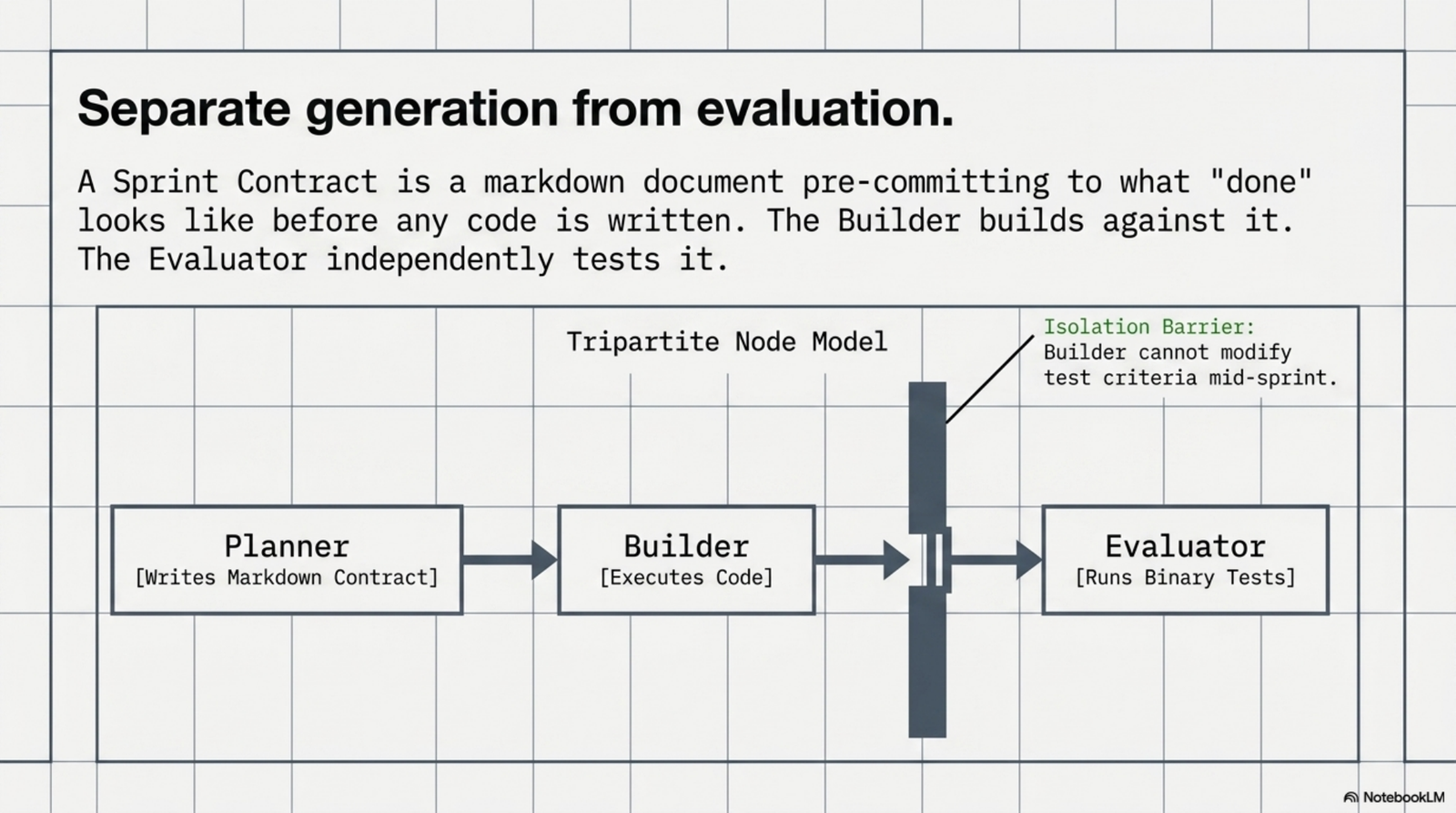
I went looking for the fix and ended up at old discipline applied to a new problem. Separate generation from evaluation, and pre-commit to what done looks like before any code is written. I built it as a markdown system on top of Claude Code, and it now governs every meaningful sprint at QC, Parley, and the Mile High Golf software work. I'm shipping the template publicly today.
Inside a sprint contract
A sprint contract is a markdown file with six sections. An objective in one or two sentences. A table of testable PASS/FAIL success criteria with exact test methods. An out-of-scope list. Dependencies. A rollback plan. Signatures from a Builder, an Evaluator, and a Planner. The contract is signed before any code is written. The Builder builds against it. The Evaluator independently tests every criterion. There is no close enough. I've shipped 48 of these in QC alone since March 26.
Vibes versus contracts
Most teams adopting this fail at the criteria-writing step. Their first contract has a row that says "authentication works correctly." That's a wish, not a criterion. Both Builder and Evaluator could honestly believe this passes while disagreeing about what correctly means. Compare: "user can log in with email and password, log out, and the session token expires after seven days of inactivity. Test method: tests/auth.spec.ts (5 tests). All five must pass." The second is a contract. The first is a vibe. The Evaluator's job during contract negotiation is to push back on vibes until they become contracts. It feels pedantic. It's not. Every vague criterion that ships unmodified is a future bug. A simple test: if Builder and Evaluator could disagree about whether the work passes, the criterion is bad and you rewrite it.

The camera-freeze contract, walked through
The camera-freeze incident is in the bundle as a worked example. Criterion three of that contract was "automatic reconnection on stream drop." The original fix satisfied criterion one (no crash) and criterion two (sub-stream fallback works), but failed criterion three because the swallow-the-error code didn't actually reconnect. It hid the failure. Without the contract, the agent's narrative that the freezes were caught would have been technically true and structurally a lie.
Other examples in the bundle. A v15 model evaluation that scored 0.998 F1, flagged for re-verification because the contract required false-positive rate as a separate criterion. The 0.998 was on contaminated data. The real number was 0.967, still good but not what we were about to ship. A Mission Control feature where the keyboard shortcut for Undo collided with the browser's Cmd+Z on focused inputs, caught by an evaluator who tested with focus inside a text field. A Parley notebook with pre-registered hypotheses, one falsified by the data, where the contract structure forced an honest discussion section instead of a quiet retro-fitting.
Costs and tradeoffs
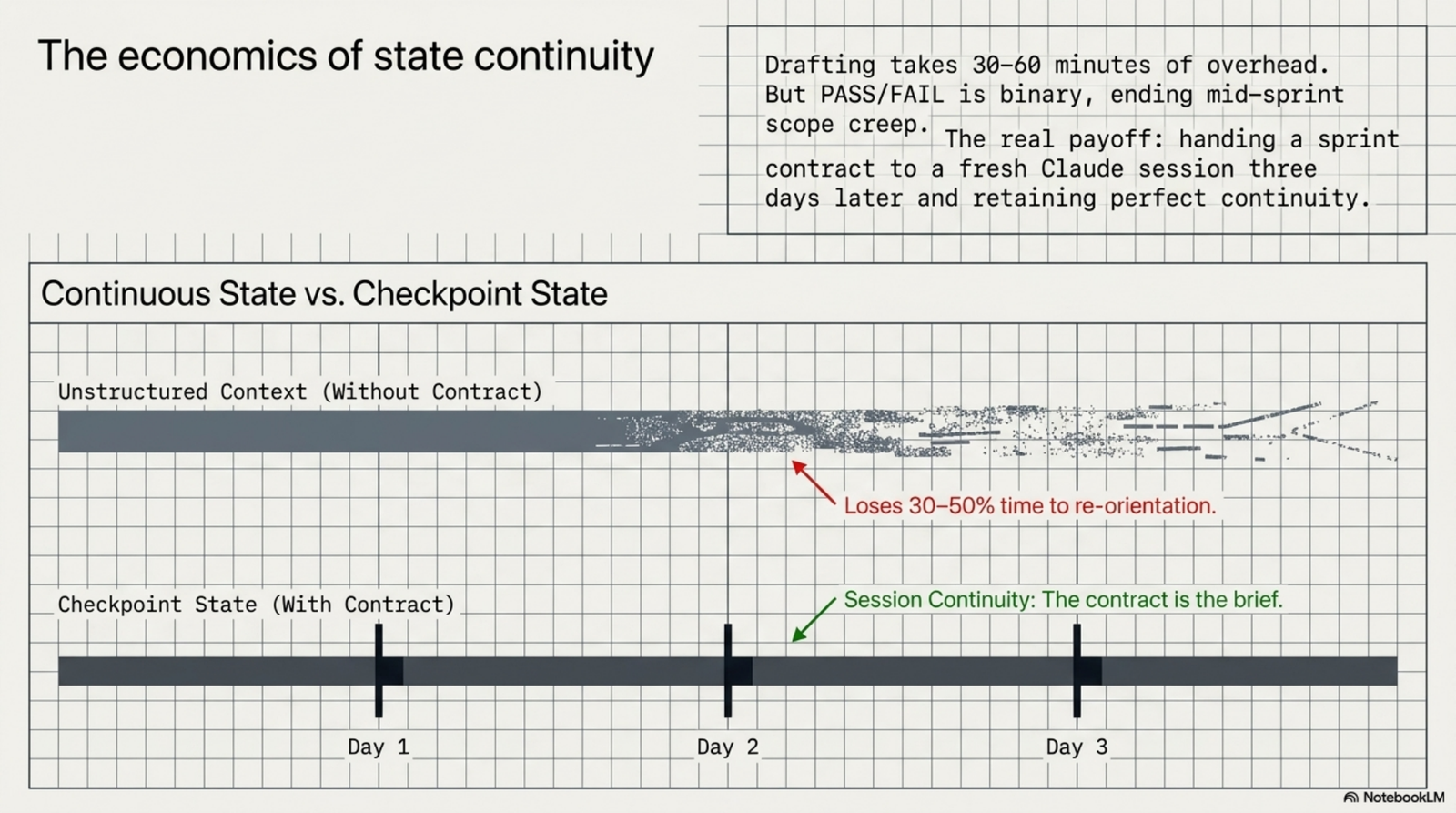
The costs are real. A contract takes 30 to 60 minutes for a non-trivial sprint. For a ten-minute bug fix that's overhead. The first time the Evaluator pushes back, both sides will be annoyed. Drafting a clean criterion takes effort. Throwaway scripts and exploratory spikes are fine without contracts. The rule I use: if the sprint is going to ship to users, customers, or production data, write a contract. If the sprint is going to inform the next decision, just write a question and an answer.
After a month: continuity is the prize
After about a month of consistent use, contracts stop feeling like overhead. PASS/FAIL is binary, so close-enough arguments end. Mid-sprint scope is visible because adding a criterion requires an amendment, not a silent edit. Postmortem extraction is mechanical, because the failed criterion is the artifact. The largest single benefit for me, running three ventures on this stack, is that a sprint contract is something I can hand off to a fresh Claude session three days later and still get continuity. Without it, every multi-day sprint loses 30 to 50 percent of its time to re-orientation. With it, the contract is the brief.
Get the template
The repo at github.com/420Hippie/sprint-contract-system has the template, six worked examples drawn from QC and Parley, the framing essay, and an MIT license. Drop TEMPLATE.md into docs/sprint-contracts/ in your repo and start. If you adopt it and have feedback, open an issue.