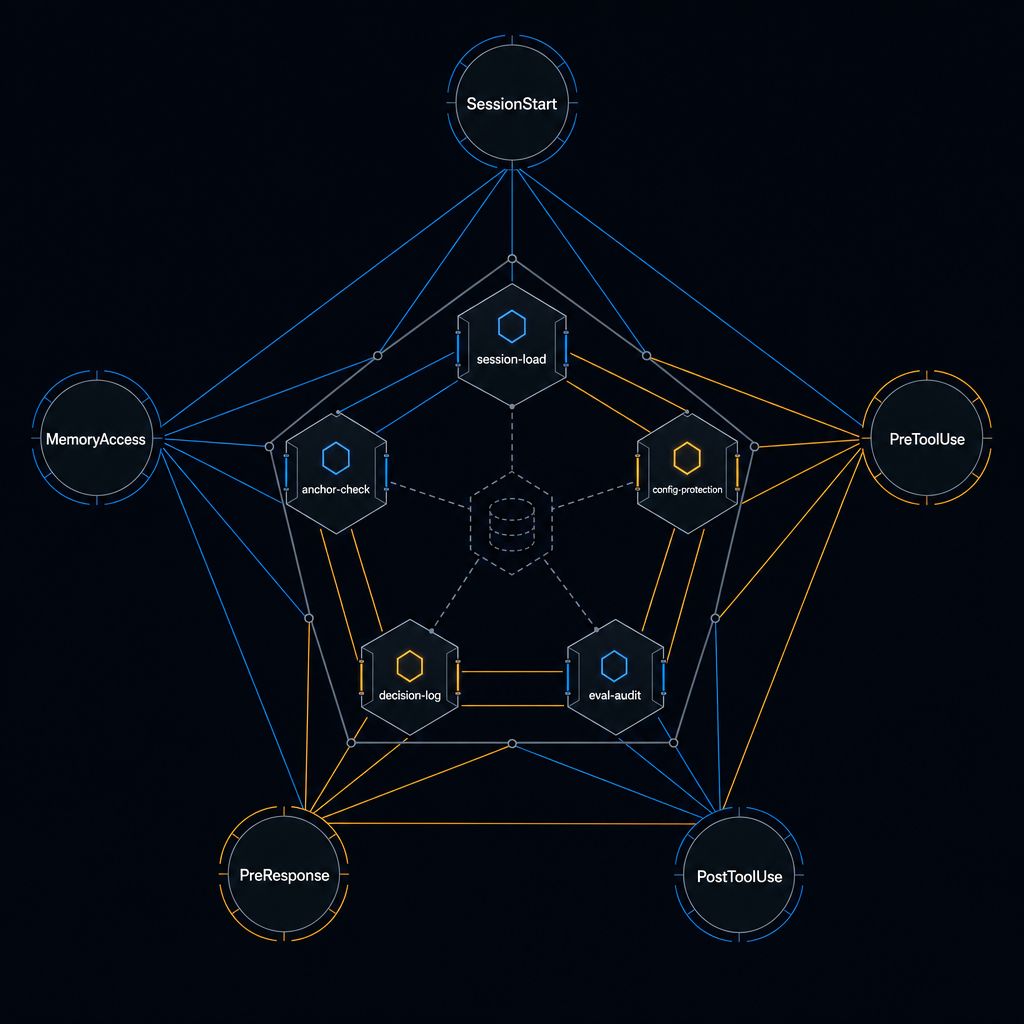
Hooks Bundle
Five production-tested Claude Code hooks — session loading, config protection, eval auditing, decision logging, anchor-check cadence. The mechanical enforcement layer your CLAUDE.md rules have been promising.
- All 5 hooks read real Claude Code JSON input — none is pseudocode
- Config-protection hook prevents the class of incident that cost 4.5 hours of test setup
There's a rule in my CLAUDE.md that I wrote three times before I understood why it kept getting violated.
"Don't modify production configuration files without explicit operator confirmation."
I worded it differently each time. I added it to memory. I put it near the top of the file, in bold, with a reason attached. The agent would read it at session start. The agent would agree, if asked, that the rule was correct. And then, deep in a session, doing something unrelated, a script would run with a side effect the agent hadn't traced through — and the config would change.
The rule wasn't wrong. The enforcement mechanism was wrong. I was using memory to enforce something that needed a hook.
The fourth time I addressed it, I stopped rewriting the rule and wrote a five-line bash script instead. The script fires before every Edit and Write call, reads the target file's header, and blocks if it finds a SACRED marker. From that point forward, the rule has never been violated. Not because the agent became more careful — because the violation is now structurally impossible through the Edit and Write tools.
That's the entire thesis of this bundle: mechanical enforcement is always more reliable than promised future discipline. Not more powerful, not more intelligent — just more reliable. A hook fires at its registered moment every time, independent of what the agent was focused on, independent of how long the session has been running, independent of whether the rule was near the top of CLAUDE.md or buried three pages in.
The five hooks
Session-start memory load — On startup or resume, locates and prints the project's active constraints file, memory index, and current sprint contract's success criteria. This information loads into session context before the first prompt processes. The agent begins with its current operating constraints in front of it rather than in background memory.
Config protection — PreToolUse on Edit and Write. Reads the first 30 lines of the target file. If it finds the SACRED marker (the string "# SACRED" in shell files, or "__sacred": true in JSON), it blocks with exit code 2. There's a single-session bypass via environment variable — SACRED_BYPASS=1 — that produces an audit line in stderr. Deliberate edits are always possible; accidental ones are not.
Eval overlap audit — PreToolUse on Bash. Scans the command string for patterns that suggest an evaluation run (evaluate.py, run_eval, f1_score, mAP, and eight others). If matched, it injects a warning: before accepting any result from this eval, confirm training and test sets are from distinct source files, and treat F1 > 0.95 as NEEDS-VERIFICATION, not gate-passing. The hook warns; it never blocks. An eval that fires a false-positive block is workflow-breaking. An eval that fires a false-positive warning costs one second of reading.
Decision log — PostToolUse on Edit and Write. After any major file edit (over 200 characters of new content, or matching a list of always-log path patterns), appends a structured JSON line to decisions.jsonl: timestamp, tool name, file path, session ID. Async by design — it never slows the main session. The log is append-only and lightweight. After a few months of use, it becomes the most useful single artifact for reconstructing why a file looks the way it does.
Anchor-check cadence — UserPromptSubmit, no matcher. Fires when 60 minutes have elapsed since the last anchor (tracked via .claude/last-anchor). Injects a two-sentence reminder: confirm what the current objective is, confirm whether this prompt is in scope. One sentence from the agent in response is sufficient. The reminder addresses a specific drift pattern: sessions running past 90 minutes without explicit reorientation tend to accumulate small scope expansions that compound into significant off-track work.
Why the exit code matters
Claude Code hooks use a specific exit-code protocol:
- Exit 0: success. Stdout is injected as context (for SessionStart, UserPromptSubmit) or logged.
- Exit 2: blocking error. Stderr is shown to Claude. The tool call is blocked.
- Any other non-zero: non-blocking error. First line of stderr appears in the transcript; execution continues.
Exit code 1 is non-blocking. This is counterintuitive and the most common hook-writing mistake. If you want to enforce a policy — actually stop the tool from running — you must exit with code 2. The config-protection hook exits 2. The eval-overlap and decision-log hooks exit 0 because they warn without blocking. Understanding this distinction is the difference between a hook that enforces and a hook that narrates.
What breaks when hooks go wrong
Hooks can fail in three directions.
Over-eager blocking. A PreToolUse hook fires on too broad a pattern — every Edit regardless of file type, every Bash command regardless of what it does. Within a week the operator is using manual bypass paths for everything and the hook is a tax, not a guardrail. The fix: tighten the predicate. The config-protection hook fires only on files with the SACRED marker. The eval-overlap hook fires only on commands matching one of twelve specific patterns. If you find yourself bypassing a hook more than once a week, the predicate is wrong.
Silent non-fire. The hook is registered, but the matcher doesn't match the actual tool name Claude Code uses internally. Nothing fires, the failure the hook was supposed to catch keeps happening, and the operator doesn't know the hook isn't working. Fix: test every hook explicitly — trigger the exact condition and verify the expected output. A hook is wrong until proven right.
Stale conditions. A hook was written when a file was at config/camera_params.json. After a refactor it moved to config/capture/params.json. The SACRED check no longer fires on the right file. Fix: audit hooks when you audit CLAUDE.md — roughly monthly — and verify that every hook's condition still matches something real.
When NOT to add a hook
This is the section most bundles skip.
Don't add a hook when the rule it would enforce has never been violated. Hooks are for patterns that have actually broken something, or whose failure mode is clear enough and costly enough to justify preemptive enforcement. A hook for a hypothetical failure is overhead that hasn't earned its place.
Don't add a PreToolUse blocking hook when the failure is recoverable. If the cost of the action going wrong is "run it again" or "git reset," PostToolUse logging is a better fit than PreToolUse blocking.
Don't add a hook when the real problem is a vague CLAUDE.md rule. A hook enforcing a vague predicate fires in the wrong places. Write the rule precisely enough that you can express it as an exact file pattern or command string before adding the hook. If you can't write the exact predicate, you don't yet know what you're trying to enforce.
Don't add a hook as a substitute for a structural fix. If the same class of incident keeps recurring despite a hook, the hook's predicate is wrong and you need to understand why the failure keeps slipping through. More hooks won't fix a predicate that misses the actual failure mode.
Lineage
The config-protection hook came directly from an incident where a pre-flight script's auto-detect call overwrote a verified production configuration file. Four and a half hours of calibration work, gone in one function call. The incident was postmortem'd. The structural fix was the hook.
The anchor-check hook came from observing that sessions running past 90 minutes without an explicit scope check consistently produced work that was individually reasonable and cumulatively off-track. The 60-minute cadence was tuned through trial — 30 minutes fired too often, 90 minutes was one full drift cycle too late.
The decision log is the cheapest habit in this bundle. It produces one JSON line per major edit. Six months from now, when you're trying to understand why a file changed, the log is there.
— Michael, from the lab