Pre-register the recipe before you rank architectures
A shared training recipe across architectures does not control for the recipe. It bakes it into the result and disguises it as an architecture finding. Four cheap controls keep the ranking honest.
- Why a shared recipe measures the recipe, not the model
- The four controls: per-architecture recipe, one hardware, seed spread, shuffled-label check

The clean-looking way to compare architectures is to hold everything else constant and vary only the architecture: same learning rate, same schedule, same regularization, same hardware, same everything else. It reads as the careful, scientific control. Change one thing, measure its effect.
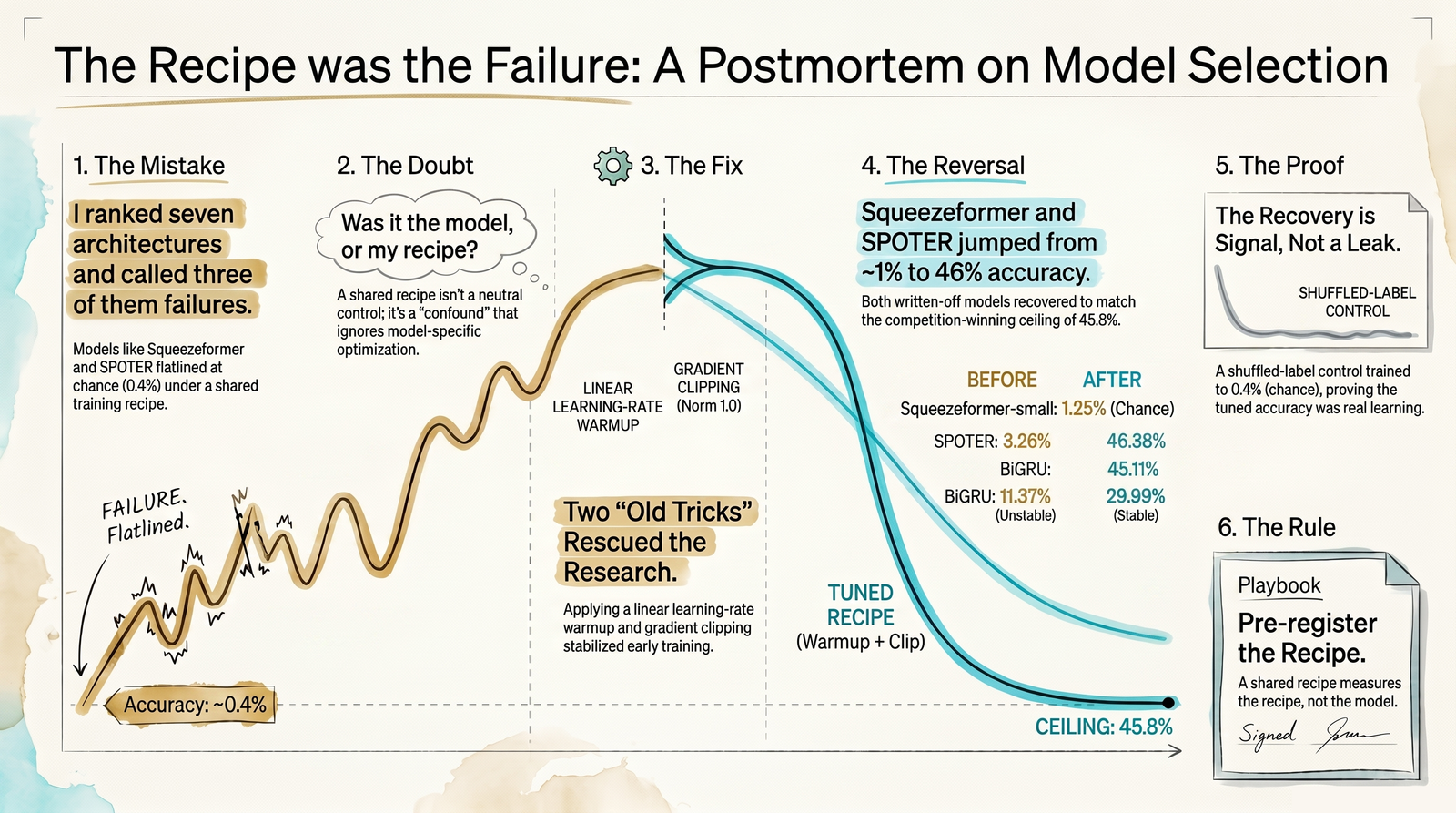
It is the wrong control, and it produced a result I had to walk back. In a Parley sign-recognition notebook I ranked seven landmark architectures on a cross-signer ASL task under one shared recipe, reported three of them as failures, and was wrong about all three. A per-architecture recipe brought every one of them back, and two of the three matched the best model on the board. The ranking I had published was not a ranking of architectures. It was a ranking of how well one recipe happened to fit each architecture. This chapter is the discipline that stops that mistake.
Why "hold the recipe fixed" is not a control
A training recipe is not a neutral background you can hold constant the way you hold the random seed or the dataset constant. The recipe interacts with the architecture. Different architectures have different optimization geometries and want different opening moves.
The clearest case is learning-rate warmup. A transformer-family encoder started without a warmup takes its first few optimizer steps at full learning rate, and those early steps can be large enough to throw the model out of the basin it was initialized in. Once it's out, it doesn't come back: the loss rises instead of falling and the model spends the entire run at chance. A recurrent model with a different loss surface might tolerate the same opening fine. So a single shared recipe, tuned implicitly around whichever architecture you had in mind when you set it, will train that one cleanly and destabilize the others. When you then report "Architecture X collapsed," you have measured the recipe's misfit with X and labeled it a property of X.
The general statement: when you fix the recipe across architectures, the recipe stops being a control and becomes a confound. The published ranking measures recipe-fit, not architecture quality, and nothing in a shared-recipe comparison can tell the two apart.
Counting the cost
The Parley numbers are the worked example. The three are all landmark-sequence models: BiGRU is an older recurrent network that reads the motion forward and backward, SPOTER a transformer built for sign language from body and hand pose, and Squeezeformer a transformer borrowed from speech recognition and adapted to landmarks. Under the shared recipe, Squeezeformer-small sat at 1.25% on a 250-class task where chance is 0.4%. It looked dead. SPOTER looked nearly as dead at 3.26%. BiGRU was unstable in a different way: one seed of three would find a real number and the other two would collapse, so its "result" depended on the draw.
Under a per-architecture recipe (a learning-rate warmup and gradient clipping, nothing exotic), Squeezeformer went to 46.38% and SPOTER to 45.11%, both landing on the competition-winning model's ceiling of 45.77%. The architectures I had written off as broken were, correctly trained, as good as the best model I had. The published failure verdict was an artifact of my recipe, and any engineering decision made off that verdict, such as "don't use Squeezeformer for this," would have been wrong.
Four controls that keep it honest
The fix costs no new data. It is four controls, declared before the runs.
Pre-register a per-architecture recipe: each architecture gets its own learning rate, warmup length, and clipping, written into a contract before anything runs. The point of writing it first is that you can't quietly tune one architecture to a better number after seeing the results and call it a fair comparison. The recipes don't have to be elaborate; a warmup and a gradient clip rescued all three of mine. They only have to be per-architecture and fixed in advance.
Run the whole ladder on one hardware, to convergence: mixed hardware is a second confound stacked on the first. A collapse on one backend can be a numerical-stability quirk of that backend rather than the recipe. Run every architecture on the same device, and train to convergence rather than a wall-clock budget, so a slow-but-fine architecture doesn't get scored as a failure for running out of time. My BiGRU verdict actually flipped between my Mac and the GPU, a reminder that a fragile architecture is sensitive to hardware as well as seed.
Report the seed spread next to every mean: run at least three seeds and publish the dispersion, not just the average. A single-seed number can't distinguish "this architecture trains reliably" from "this architecture trained once and I got lucky." If the seeds disagree wildly, the architecture isn't really at that number. The lottery-ticket failures are invisible without this.
Include a shuffled-label control: when an architecture's accuracy jumps after a pipeline change, prove the jump is signal and not a leak you introduced. Train the same model on deliberately shuffled labels; it should land at chance. My tuned model on shuffled labels hit 0.39% against a 0.4% floor, which is clean. Without this check, a recovery this large should not be trusted, including by you.
When this discipline applies, and when it doesn't
This is for any comparison where the headline is "which architecture is better for this task" and the conclusion will drive a real decision: a model selection, a published benchmark, a claim that some architecture family doesn't work on some problem. That's where a recipe confound does the most damage, because the failure verdict reads as permanent and gets cited as settled.
It applies less when you are deliberately testing one fixed recipe. "Given exactly this training budget and these hyperparameters, which architecture wins" is a legitimate question, as long as you report it that narrowly and don't generalize the loser to "Architecture X can't do this." The sin isn't using a shared recipe. The sin is using a shared recipe and then making an architecture claim the recipe can't support. It also applies beyond sign-language CV: any venture comparing model families on its own data inherits the same trap, and the cheaper and more uniform the comparison looks, the more likely the recipe is quietly deciding the ranking.
The rule
Before you rank architectures, pre-register a per-architecture recipe, run the ladder on one hardware to convergence, report the seed spread with every mean, and include a shuffled-label control. A shared recipe is not a fair fight; it is a measurement of your recipe wearing the architecture's name. The four controls cost a little discipline and no new data, and they are the difference between a ranking you can act on and one you'll have to retract.