The Honest Ceiling on Landmark-Only Isolated-Sign Recognition: A Signer-Holdout Audit
Abstract
Isolated-sign recognition results are routinely reported in the 80-90% range, but most are measured on signer-mixed splits where the same signers appear in both training and test data. We audit the real landmark-only ceiling on a strict signer-holdout split of the Google ISLR dataset (250 signs, a 17/2/2 train/val/test signer split, mean and standard deviation over three seeds). The best stable architecture, a frame-level transformer, reaches 44.7% top-1 (+/- 1.0); hand-shape features alone reach 36.4%, so the full body-and-face landmark set adds only about eight points over the hands. Three of seven architecture families collapsed to near-random accuracy on two or more of three seeds, an instability that single-seed reporting would hide entirely. We argue that signer-holdout evaluation with multi-seed reporting is the minimum honest protocol for this task, and that the gap between leaky-split and signer-holdout numbers is the single most important figure a sign-recognition result can disclose.

1. Introduction
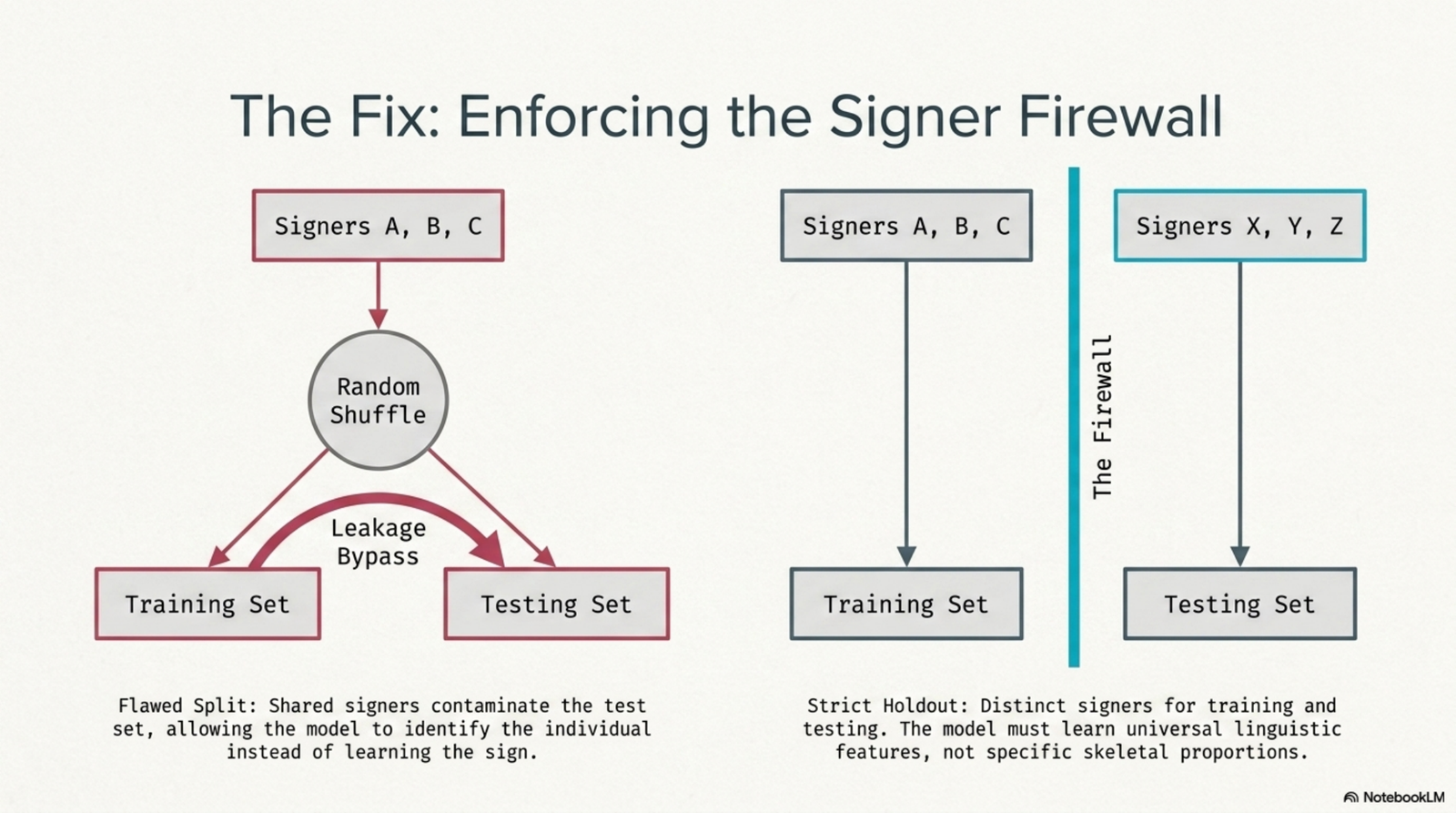
A reader scanning isolated-sign recognition results comes away with the impression that the problem is mostly solved. Accuracy numbers in the 80-90% range are common, both in published work and on public leaderboards for datasets like Google ISLR [1]. The impression is misleading, and the reason is the evaluation split. Most of those numbers are measured on signer-mixed data, where the same people who appear in training also appear in test. The model is rewarded for memorizing how a specific person signs, and the score it reports is not the score a deaf user in the wild would experience [3].
The honest version of the question is: how well does a landmark-only model recognize signs from people it has never seen? We answer it on the Google ISLR dataset, restricted to 250 signs, with a strict signer-holdout split and results reported as mean and standard deviation over three random seeds. We are not proposing a new architecture. We are establishing a credible ceiling and documenting the failure modes an optimistic evaluation would have hidden.
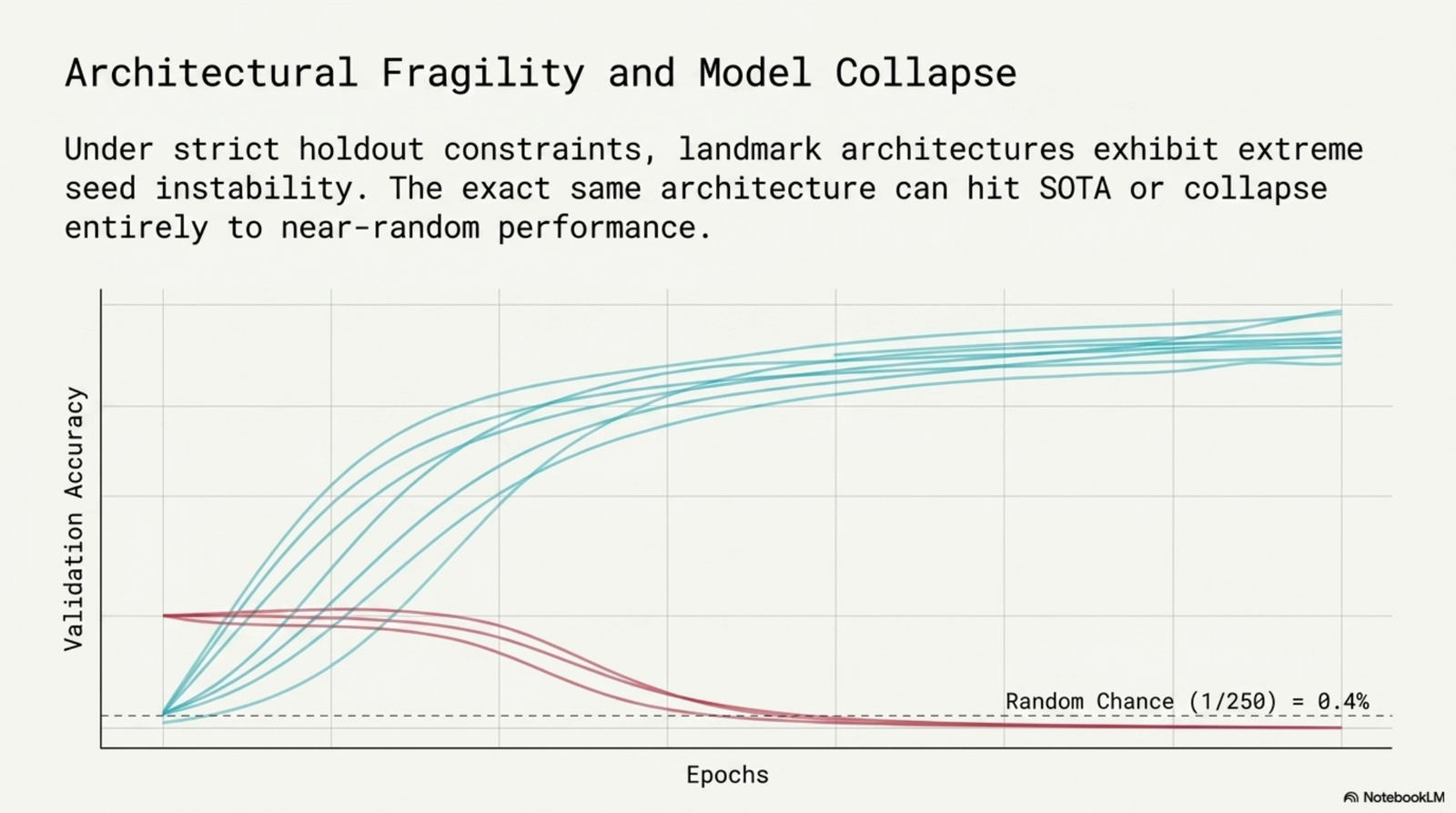
The headline result is that the best stable model we trained reaches 44.7% top-1 on held-out signers, less than half what signer-mixed reporting suggests. Two further findings matter as much as the number itself: hand-shape features alone account for most of that accuracy, and several otherwise-reasonable architectures collapsed to near-random performance on a majority of seeds.
The rest of TPL-2026-023 is for subscribers.
The Honest Ceiling on Landmark-Only Isolated-Sign Recognition: A Signer-Holdout Audit
- Every Expert-tier lesson — diagnostic prompts, transcripts, prompt kits, full homework
- Every research paper — methodology, figures, tables, reproducibility appendices
- New Expert lessons + papers as they ship (quarterly cadence)
- Foundations + Operating lessons stay free; bundles on GitHub stay free; this tier is the deep stuff
Free while the early catalog ships. Paid tier comes later — subscribe now and you’re grandfathered in.