Recipe, Not Architecture: Three "Failed" Sign-Recognition Models Recover Under Per-Architecture Training
Abstract
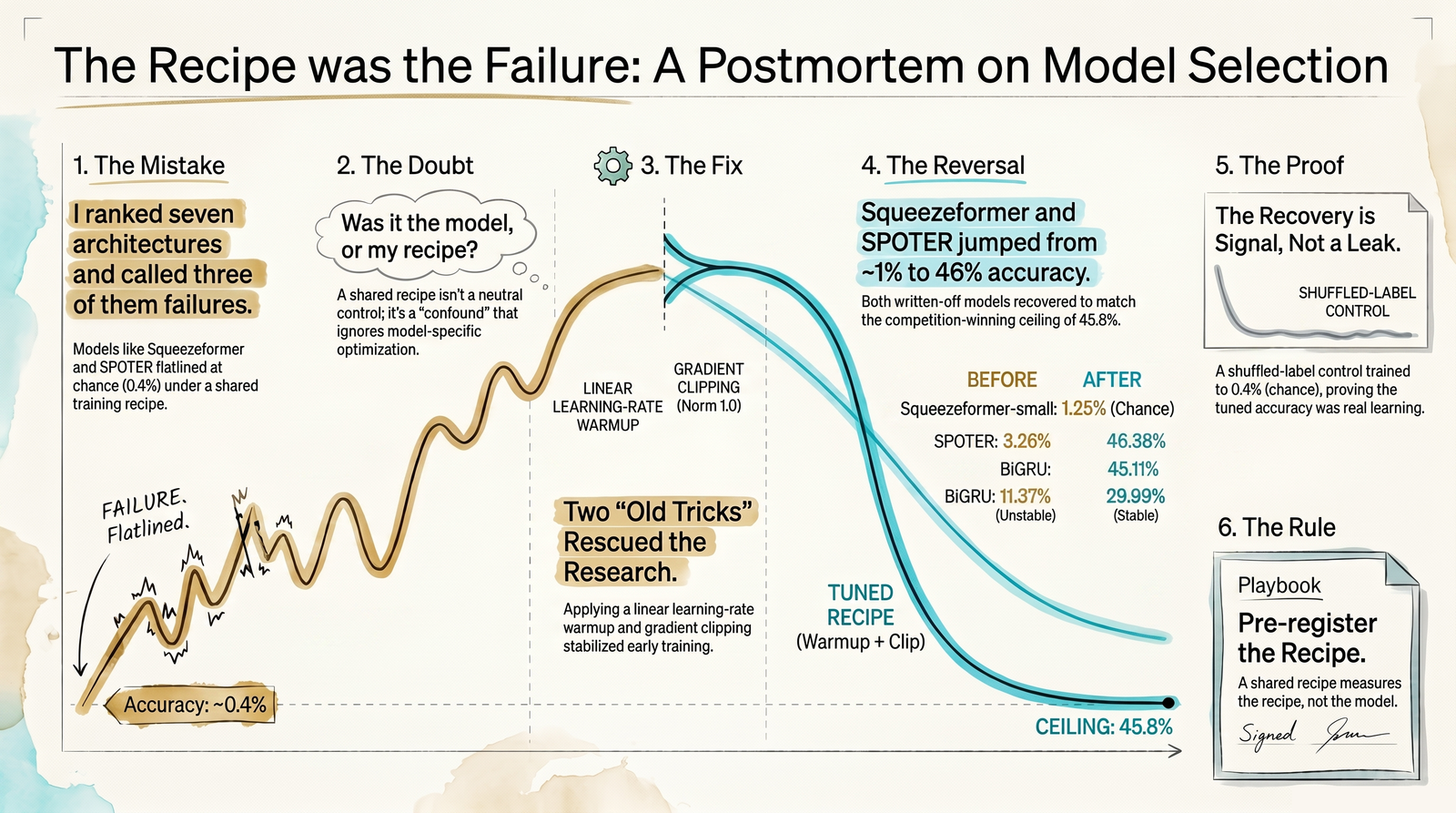
Architecture comparisons in sign-language recognition are routinely run under a single shared training recipe, and the resulting ranking is reported as a property of the architectures. We test that assumption directly. In an earlier signer-holdout study on the Google ISLR dataset (250 signs, 21 signers), three landmark-sequence architectures appeared to fail under a shared recipe: Squeezeformer-small collapsed to chance, and BiGRU and SPOTER were lottery-ticket, with one of three seeds training and the other two collapsing. Here we re-run each architecture under both the original shared recipe and a per-architecture tuned recipe (linear learning-rate warmup plus gradient clipping), with the full ladder on one hardware (CUDA, RTX 4090), three seeds each, every rung trained to early-stop convergence. Under a pre-registered recovery criterion (seed dispersion std/mean <= 0.10 and tuned >= 2x old), all three architectures recover. Two of them, SPOTER (45.1%) and Squeezeformer-small (46.4%), reach the competition-winning frame-transformer ceiling (45.8%) on the same honest split. A permuted-label control trains to 0.39% (chance), confirming no label leak. The reported architecture failures were substantially training-recipe artifacts, not architecture limits, and the original ranking measured the recipe more than the model. We make no state-of-the-art claim; the contribution is a methodological correction with a worked example.
1. The question this paper closes
This is the fourth installment from Parley's research arm on the Google ISLR dataset. The first three are public: a hand-shape baseline, an architecture ceiling-search that put honest cross-signer accuracy at 44.7% against the roughly 83% random-split leaderboard number [9], and a 21-fold leave-one-signer-out study that found a 38.57-point fairness spread across signers.
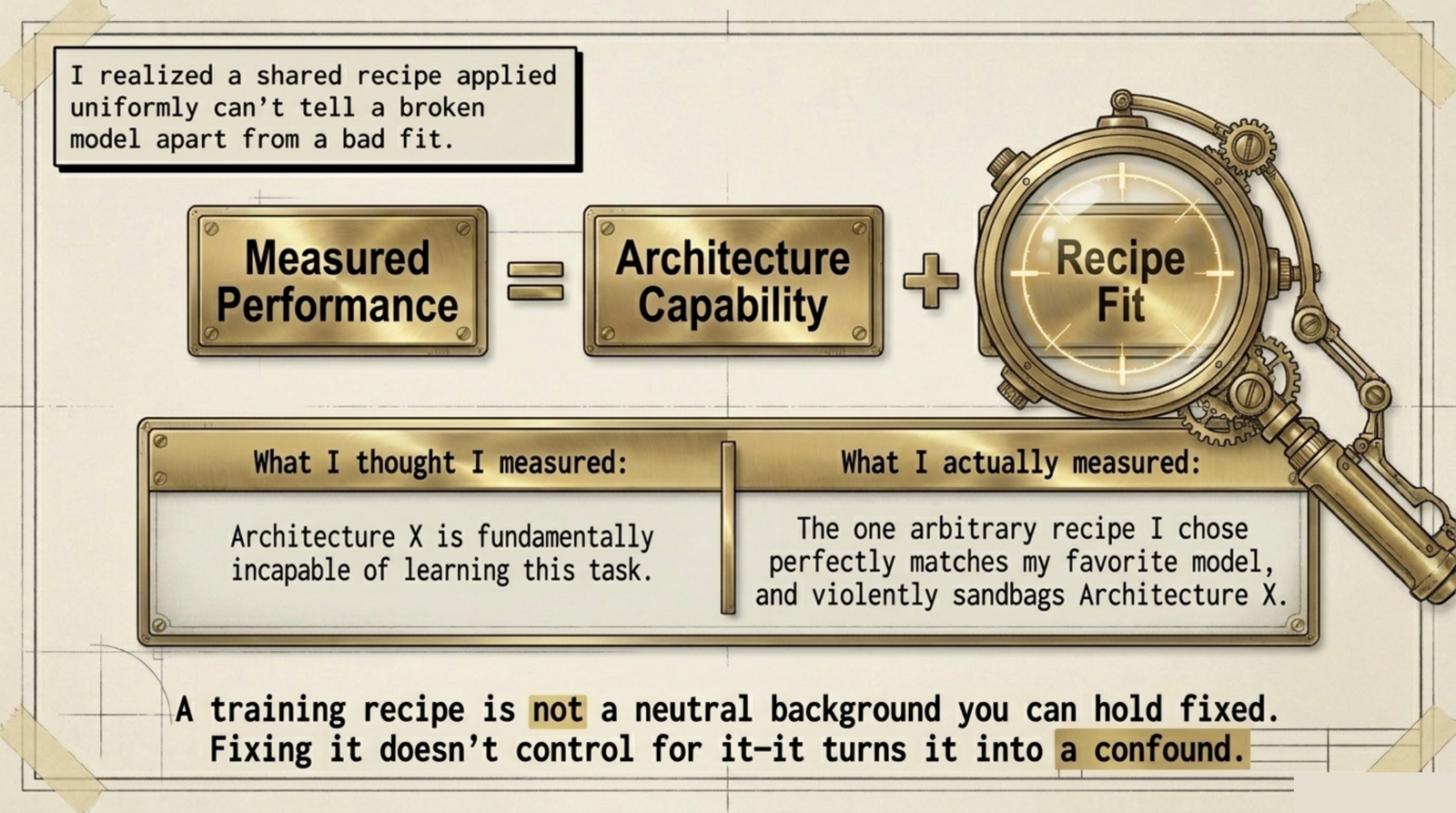
The ceiling-search left a loose end. Of the seven architectures on the ladder, several did not behave. Squeezeformer-small collapsed to chance and stayed there. BiGRU and SPOTER were what the lottery-ticket literature [1] would call untrainable-by-init: one seed of three found a working basin, the other two sat at chance. Under a shared training recipe, one learning rate, one schedule, one set of regularization choices applied uniformly to every architecture, these looked like architecture failures. The honest version of that finding raised a question instead of answering one: were these architecture limits, or were they recipe artifacts that a shared recipe could not have distinguished from limits?
The cast, briefly: BiGRU is a bidirectional gated-recurrent sequence model that reads the landmark stream forward and backward in time; SPOTER [6] is a transformer built for sign language from body and hand pose; and Squeezeformer-small [5] is a convolution-augmented, downsample-recover transformer adapted from automatic speech recognition. The reference ceiling is the competition-winning frame-level landmark transformer.

That question is the whole paper. It matters beyond Parley because shared-recipe architecture comparisons are the default in applied sign-language work, and a shared recipe that happens to suit one architecture's optimization geometry will systematically flatter it and bury the others.
The rest of TPL-2026-025 is for subscribers.
Recipe, Not Architecture: Three "Failed" Sign-Recognition Models Recover Under Per-Architecture Training
- Every Expert-tier lesson — diagnostic prompts, transcripts, prompt kits, full homework
- Every research paper — methodology, figures, tables, reproducibility appendices
- New Expert lessons + papers as they ship (quarterly cadence)
- Foundations + Operating lessons stay free; bundles on GitHub stay free; this tier is the deep stuff
Free while the early catalog ships. Paid tier comes later — subscribe now and you’re grandfathered in.