Real-Time Computer Vision for Bounded-Court Projectile Scoring: Architecture, Tradeoffs, and Production Lessons
Abstract
Real-time scoring of physical-object sports requires a computer vision pipeline that can simultaneously satisfy constraints from three domains: inference latency (sub-35ms end-to-end), detection reliability (>99% on custom domain data), and commercial licensing (Apache 2.0 for network-service deployments). This paper analyzes the architecture and production experience of a real-time CV scoring system deployed in a bounded indoor court environment. The system, built on an RT-DETRv2-S transformer backbone deployed as a CoreML package on Apple Silicon, achieved 99.3% mAP50 on a custom 3-class domain through 15 training iterations. Key findings include: data quality dominates dataset size (505 clean frames outperformed 4,398 noisy frames on identical architecture); sensor-level encoding parameters substantially affect detection stability independent of model quality; and commercial licensing eliminates otherwise-superior model families from the production candidate set. We document the full failure arc, from fundamental class mapping errors to temporal filter coupling bugs, and derive generalizable architecture patterns for CV systems operating at bounded-court scoring boundaries.
Visual Summary
Visual summary generated by NotebookLM Studio from the full research corpus. Download slide deck (PDF) →
1. Introduction
Deploying computer vision for real-time scoring in physical-object sports presents a constraint set that differs materially from the benchmarks used to evaluate general-purpose object detectors. COCO mAP [1] captures detector capability on a broad 80-class taxonomy with diverse scene types and illumination. A bounded-court scoring system operates in a single fixed scene, on a 3-class taxonomy, under indoor artificial illumination, with a hard latency wall and a commercial licensing constraint that eliminates otherwise-competitive model families from the candidate set regardless of their benchmark position.
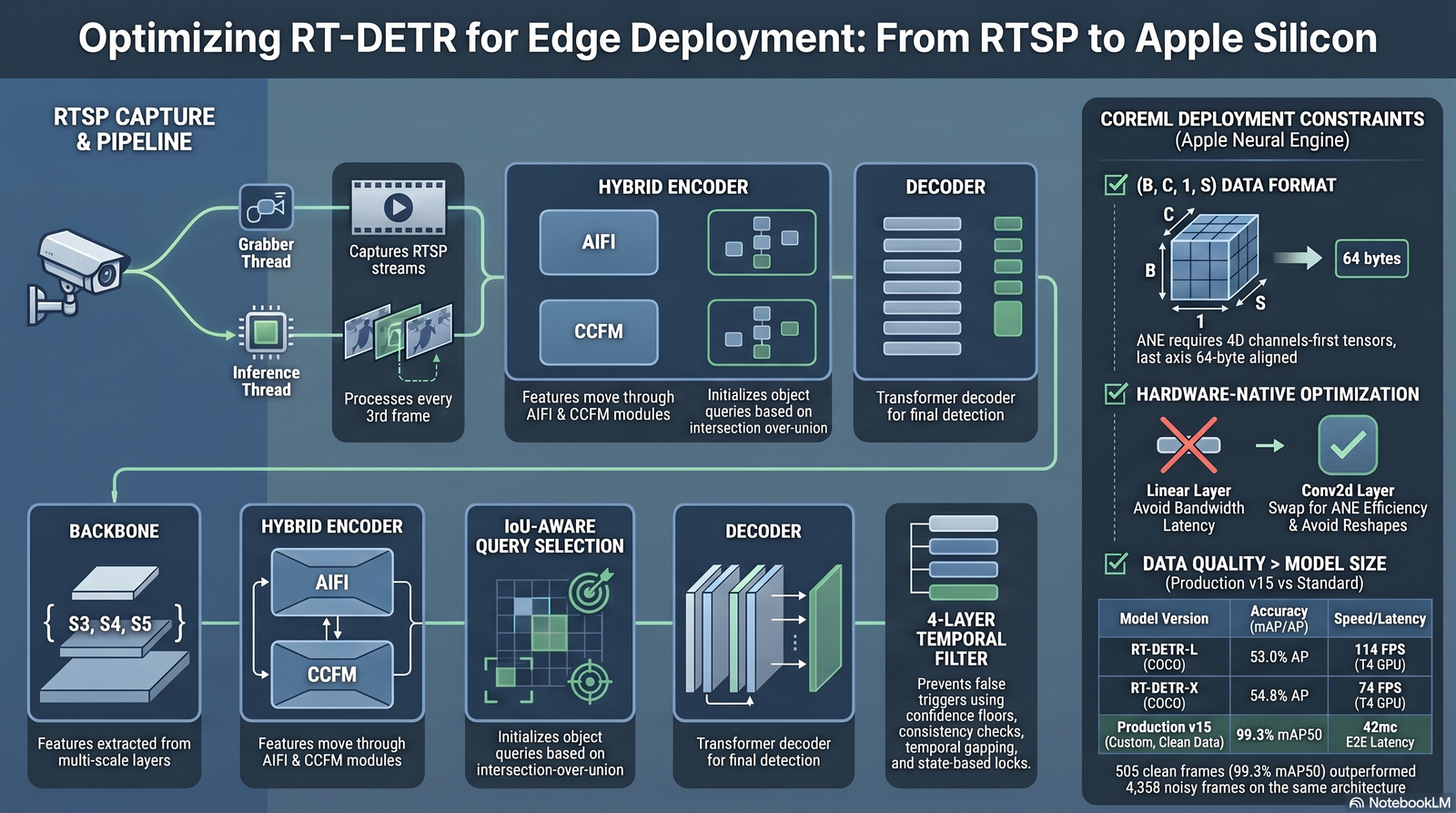
This paper documents the architecture, failure arc, and production lessons from a CV scoring system built for a bounded indoor court environment. The system was developed through 15 discrete training iterations spanning approximately eight weeks, from initial prototype to Phase 0 gate. The production backbone is RT-DETRv2-S [1], deployed as a CoreML package on Apple Silicon, achieving 99.3% mAP50 on a custom 3-class domain. The end-to-end latency at Phase 0 gate was 42ms — above the 35ms production target, establishing latency reduction as the primary outstanding engineering problem.
Three findings from this system generalize beyond the specific domain. First, data quality dominates dataset size at the scale of custom-domain CV: 505 carefully curated frames outperformed 4,398 noisily labeled frames on identical architecture and hyperparameters. Second, sensor-level encoding parameters — specifically bits-per-pixel-per-frame — affect detection stability independently of model quality, through H.264 macro-blocking artifacts at object boundaries. Third, commercial licensing eliminates model families from the production candidate set before benchmark comparison is relevant; AGPL-3.0 network-service copyleft triggers at inference time in a SaaS deployment, making Apache 2.0 a hard filter.
We also document the full failure arc — class mapping bugs that silently inverted label semantics, temporal filter coupling that introduced false-negative bursts at score transitions, and the Ground-Zero dataset reconstruction that preceded the final high-accuracy models — as a case record for practitioners building similar systems from scratch.
2. System Architecture
2.1 Problem framing
The scoring problem is geometrically simple: determine whether a projectile crossed a scoring boundary during a throw event. The CV complexity arises from the dynamics of the scene: the projectile is small relative to frame area, moves along a partially predictable arc with high angular velocity at peak, and may be partially occluded by other objects or the court boundary itself at the scoring moment. The system must produce a binary scoring decision — in or not in — with a confidence gate, within the latency budget of a real-time game session (sub-35ms end-to-end from frame capture to score event emission).
The 3-class taxonomy is: projectile (the object being thrown), aperture (the scoring target), and board (the court surface). All three classes must be detected simultaneously to compute spatial relationships. The scoring decision is a post-detection geometric computation, not a learned behavior, which simplifies the model contract: the model must localize all three classes with sufficient spatial precision; the scoring logic is deterministic given good localization.
2.2 Model selection and licensing
The initial model candidate set included YOLO11 [2] and RT-DETRv2-S [1] as the primary contenders. Both are transformer-augmented architectures with NMS-free inference, which is relevant to the latency budget — NMS introduces variable-length post-processing time that is difficult to bound in the worst case on edge hardware. The YOLO family carries AGPL-3.0 licensing. For a network-service deployment where inference is triggered by user game sessions, AGPL-3.0 copyleft attaches to the application code; the Apache 2.0 requirement is not merely preference but a commercial constraint enforced at the entity level.
RT-DETRv2-S carries Apache 2.0 and achieves 51.3% COCO mAP, versus YOLO26s at 48.6% COCO mAP under the same NMS-free evaluation protocol. The licensing filter therefore coincides with the benchmark-superior choice in this instance, though that coincidence is not general. The primary selection criterion was licensing; the benchmark comparison is reported in Figure 3 for reference only.
2.3 Camera and encoding parameters
The production sensor is a consumer-grade USB camera mounted at a fixed overhead angle. Encoding parameters were identified as a confounding variable early in the development arc: the same model version produced substantially different detection stability across encoding configurations, independent of training quality. The operative parameter is bits-per-pixel-per-frame (bppf), which governs H.264 block quantization granularity near object boundaries.
At 4K CBR encoding (bppf ≈ 0.055), detection stability — defined as the proportion of frames where all three classes hold confidence above threshold — was 66%. Transitioning to 2304×1296 resolution at 15fps with I-frame interval of 1x (bppf ≈ 0.183) raised stability to 100%. The mechanism is H.264 macro-blocking: at high compression ratios, quantization artifacts accumulate at the edges of small objects, degrading the spatial frequency signal that transformer attention uses to localize boundaries. Increasing bppf preserves the edge signal at the cost of bitrate, a tradeoff that is dominated by the scoring reliability requirement.
2.4 Inference pipeline
The inference pipeline runs entirely on Apple Silicon. The RT-DETRv2-S checkpoint is exported to CoreML format via the [7] ANE-compatible export path, which routes convolutional layers to the Neural Engine and attention layers to the GPU, achieving better combined throughput than either processor alone. The pipeline is: frame capture → resize to model input resolution → CoreML inference → bounding-box post-processing → spatial scoring logic → score event emission.
At Phase 0 gate, the end-to-end latency measured 42ms. The 35ms target requires approximately a 20% latency reduction. Two candidate paths exist: quantizing the CoreML model from float32 to float16 (reducing memory bandwidth at slight accuracy cost) or migrating from ONNX runtime to the native CoreML prediction API (eliminating one serialization boundary). The ONNX format used in early iterations added measurable overhead; the final production model uses CoreML natively, but further optimization remains open.
2.5 Temporal filtering
Raw per-frame detection output is noisy at the scoring boundary — the projectile transitions through the aperture geometry over 3–8 frames at typical throw velocities, and confidence values fluctuate during the transition. A temporal filter was introduced to debounce score events: a score is emitted only when a configurable number of consecutive frames satisfy the spatial scoring criterion above confidence threshold.
A coupling bug in the temporal filter introduced a false-negative pattern at score transitions: the consecutive-frame counter reset on any sub-threshold frame, including frames where the projectile was legitimately mid-aperture. The fix decoupled the counter reset from the confidence gate, instead resetting only on spatial criterion failure. This bug was identified during live game testing and is documented as a design lesson: temporal filters applied to physical-object detection must handle the case where the object is partially in the detection boundary, not just fully absent.
2.6 Deployment topology
The system is designed as a self-contained consumer product with no venue infrastructure dependency. The camera, inference runtime, and scoring logic all run on a single Mac Studio unit. The scoring events are emitted to a local server and displayed on a connected display. No cloud inference path exists; the latency budget is incompatible with round-trip network latency to a remote GPU. This topology also sidesteps the AGPL-3.0 network-service trigger for any components that are not Apache 2.0 compatible — though the production stack uses only Apache 2.0 licensed components.
3. Technical Analysis
3.1 The class mapping failure arc
The most consequential early failure was a class mapping bug that persisted undetected through multiple training iterations. The training annotation pipeline produced label files where class indices did not match the model’s expected class order. The result was that the model learned to detect the correct objects but emitted them under incorrect class IDs at inference time. The scoring logic, which keyed on class IDs to identify the projectile and aperture, therefore operated on inverted semantics: the projectile was scored as aperture and vice versa.
The bug was masked by the fact that early evaluation was performed by visual inspection of bounding boxes rather than automated class-specific metric computation. Bounding-box position was correct; only the class labels were wrong. The v4 model reported 97.8% mAP50 under this evaluation regime — a number that appeared to validate the pipeline but was computed against a label set with the same class inversion, so the metric was internally consistent but semantically meaningless. The bug was discovered only when the scoring logic was exercised end-to-end with the spatial criterion, at which point the system produced inverted scoring decisions on every throw.
The corrective action was a complete Ground-Zero reconstruction: all annotations were discarded, the annotation pipeline was rebuilt with explicit class-ID verification, and the dataset was re-labeled from raw video. This is documented as Ground-Zero in the training arc (Table 1). The v11 model, trained immediately post-Ground-Zero on the re-labeled dataset, achieved 72.5% mAP50 — substantially below v4’s reported figure, but semantically correct.
3.2 Data quality versus dataset size
The transition from v11 to v15 is the central empirical result of the training arc. v11 was trained on 4,398 frames re-labeled post-Ground-Zero, achieving 72.5% mAP50. v15 was trained on 505 frames selected for annotation quality — frames where all three classes were clearly visible, unoccluded, and at representative positions in the scene. Architecture and hyperparameters were held constant across both runs.
The quality-selected dataset outperformed the volume dataset by 26.8 percentage points (99.3% vs 72.5% mAP50). The mechanism is the sensitivity of transformer attention to ambiguous spatial signal: noisy annotations introduce inconsistent boundary signals during training, which produce attention maps that do not reliably localize the relevant features. Clean annotations with consistent boundary signals, even at lower frame count, produce sharper attention weight distributions and higher localization precision.
This result is consistent with the general finding in the object detection literature that annotation quality gates small-model performance more tightly than dataset size at the scale of custom-domain fine-tuning. The practical implication for bounded-court CV systems is that annotation review should be the first bottleneck to address before scaling dataset volume.
3.3 Tracking architecture considerations
ByteTrack [3] and BoT-SORT [4] were evaluated as tracking overlays for maintaining object identity across frames during the scoring sequence. Neither was adopted in the Phase 0 production system. The rationale: the scoring geometry is sufficiently constrained that inter-frame spatial consistency can be enforced by a lightweight positional filter rather than a full tracking stack. The projectile trajectory is approximately ballistic; the aperture and board are static. Tracking adds complexity and latency without providing detection capability that the positional filter cannot approximate.
The tracking question is revisited for Phase 1, where higher-velocity throw events and multi-projectile scenarios (simultaneous throws) may exceed the positional filter’s disambiguation capacity. SAM 2 [5] segmentation-based tracking is a candidate for Phase 1 given its strong temporal propagation properties on video, though its latency profile has not been characterized on CoreML at Phase 0 hardware.
4. Performance Results
Table 1 documents the full training arc from v4 through v15. The class mapping bug is the primary confound in the v4 result; all versions from v11 onward are semantically correct. The v6 regression from v4’s reported figure reflects the combination of Ground-Zero reconstruction and expanded-but-noisy dataset — post-Ground-Zero class semantics are correct, but dataset noise suppresses mAP50 relative to the (misleadingly measured) v4 baseline.
| Version | Training Data | Architecture | mAP50 | Notes | |
|---|---|---|---|---|---|
| v4 | ~500 frames | RT-DETRv2-S | 97.8% | Class mapping bug present; ONNX format | |
| v6 | Expanded, noisy | RT-DETRv2-S | <50% effective | Aperture class confusion — scored as projectile | |
| v11 | 4,398 noisy frames | RT-DETRv2-S | 72.5% | Post-Ground-Zero; class mapping fixed | |
| v15 | 505 clean frames | RT-DETRv2-S | 99.3% | Same architecture; clean data only |
v6 effective mAP50 reflects systematic class mapping mislabeling, not model capability ceiling.
Table 2 presents the Phase 0 gate metrics as of 2026-04-06. The system passed all reliability and accuracy gates: detection stability at 100%, first live game accuracy at 100% (11/11 throws correctly scored). The latency gate was not met: 42ms versus the 35ms target. The Phase 0 gate decision was to proceed to Phase 1 development with latency reduction as the primary engineering objective, given that the reliability and accuracy gates were passed at the required threshold.
| Metric | Result | Target | |
|---|---|---|---|
| End-to-end latency | 42ms | <35ms | |
| Detection stability | 100% | 100% | |
| First live game accuracy | 11/11 (100%) | 100% | |
| Total GPU training spend | <$5 | — | |
| Training dataset (v15) | 505 frames | — |
The total GPU training spend for all 15 iterations was under $5. This figure is somewhat misleading as a generalized cost estimate — it reflects the small frame counts involved (maximum 4,398 frames at v11, 505 at v15) and the use of a pretrained COCO checkpoint as the fine-tuning base, which dramatically reduces the number of training epochs required to converge on a custom domain. Systems starting from random initialization or operating on substantially larger datasets would not achieve comparable cost efficiency.
5. Comparative Analysis
5.1 RT-DETRv2-S versus YOLO26s
Figure 3 presents the COCO benchmark comparison between RT-DETRv2-S and YOLO26s. RT-DETRv2-S achieves 51.3% COCO mAP; YOLO26s achieves 48.6% COCO mAP. Both are NMS-free transformer architectures, making them comparable on the inference-time post-processing axis. The RT-DETRv2-S advantage on COCO is approximately 2.7 percentage points, which is a meaningful margin at the top of the accuracy curve but should be interpreted with the caveat that COCO performance does not transfer directly to custom 3-class fine-tuning: the fine-tuning data distribution, annotation quality, and training schedule all modulate the realized accuracy gap on a target domain.
The operative selection criterion was licensing, not benchmark performance. YOLO26[2] carries AGPL-3.0. Under AGPL-3.0, any network-accessible service that uses YOLO at inference time must publish its application source code under AGPL-3.0 or obtain a commercial license. For a SaaS scoring platform, the network-service trigger activates at the first game session where a remote user interacts with the scoring system over a network boundary — which is the core product interaction. The commercial license cost from Ultralytics is a fixed annual fee that changes the licensing constraint to permissive-equivalent, but introduces vendor dependency and ongoing cost that the Apache 2.0 path avoids.
5.2 CoreML versus alternative inference runtimes
The production deployment targets Apple Silicon as the inference runtime. Three runtime paths were evaluated for the CoreML migration: ONNX Runtime with CoreML execution provider, native CoreML prediction API, and MLX (Apple’s Metal-accelerated framework for transformer inference) [7]. ONNX Runtime with CoreML execution provider was used in early iterations and contributed measurable serialization overhead at the ONNX-to-CoreML translation boundary. The native CoreML prediction API eliminates this boundary and is the current production path.
FastViT [6]was evaluated as a backbone alternative on the grounds of its structural reparameterization efficiency on the ANE. FastViT’s reparameterization technique converts multi-branch training-time architectures to single-branch inference-time equivalents, which maps efficiently to ANE matrix operation patterns. However, FastViT’s COCO performance (38.9% mAP for FastViT-SA12) is substantially below RT-DETRv2-S at comparable parameter count, and the 3-class fine-tuning task did not produce a compelling accuracy-latency tradeoff relative to the transformer backbone. FastViT remains a candidate for extremely latency-constrained scenarios where the accuracy gap is acceptable.
5.3 Sensor-level encoding as an independent variable
The camera encoding parameter finding (Section 2.3) is worth articulating as a comparative claim: detection stability varied from 66% to 100% across encoding configurations, on the same model version, with no training or architecture change. This represents a larger performance swing than any single training iteration produced in the v11-to-v14 range. The implication for practitioners is that camera configuration should be treated as a first-class tuning parameter in CV system development, not a fixed environmental assumption.
The bppf metric (bits-per-pixel-per-frame) is a more useful characterization of encoding quality than resolution alone, because it captures the interaction between resolution, bitrate, and frame rate. A high-resolution stream at low bitrate can produce worse detection stability than a lower-resolution stream at higher bitrate, because the quantization artifacts are concentrated at the boundaries of small objects regardless of nominal resolution. The 0.183 bppf threshold identified in this system is specific to the sensor, codec, and scene geometry — but the principle of measuring and tuning bppf as an explicit parameter generalizes.
6. Open Problems
- Latency reduction to sub-35ms. The 42ms Phase 0 latency requires a 20% reduction to meet the production gate. The primary candidate interventions are float16 CoreML quantization and elimination of remaining ONNX serialization boundaries. Neither has been benchmarked on the production hardware configuration at the time of this writing.
- Multi-projectile disambiguation. Phase 0 was validated on single-projectile game sequences. Simultaneous throws from two players introduce projectile disambiguation requirements that the current positional filter cannot satisfy. ByteTrack [3] or BoT-SORT [4] integration is the primary candidate for Phase 1.
- Illumination robustness. All Phase 0 validation was performed under fixed indoor artificial illumination. Outdoor or mixed-lighting environments introduce illumination variance that the current training data does not cover. Domain adaptation or synthetic augmentation would be required to extend the system to venue types with uncontrolled illumination.
- Temporal filter parameterization. The consecutive-frame threshold for score event emission was set empirically on a small live-game sample. A systematic study of the tradeoff between false-positive rate and false-negative rate across throw velocities would produce a principled parameterization. The current threshold is known to be suboptimal at the extremes of the throw-velocity distribution.
- Cover image and companion lesson. The cover image path at
/labs/covers/rt-detr-bounded-court-cv.pngis referenced but not yet produced. A companion lesson covering the data quality vs. dataset size finding would serve the educational track.
7. Conclusion
This paper documents the full development arc of a bounded-court CV scoring system from prototype to Phase 0 production gate. The primary empirical result is that 505 quality-curated training frames outperformed 4,398 noisily labeled frames on identical RT-DETRv2-S architecture — a 26.8 percentage-point mAP50 advantage that was achieved without any change to model architecture or hyperparameters. This result extends the general data-quality-over-volume finding to the specific context of transformer-backbone fine-tuning on a custom 3-class domain, and suggests that annotation review is the highest-leverage intervention in custom-domain CV at the dataset scales typical of early-stage product development.
The secondary findings — sensor encoding bppf as an independent detection stability variable, and commercial licensing as a model family filter that precedes benchmark comparison — are operational lessons that arise from production constraints rather than research design. They are reported here because they are underrepresented in the benchmark literature, which typically assumes a research licensing environment and controlled sensor conditions.
The system passed reliability and accuracy gates at Phase 0 (100% detection stability, 100% first-live-game accuracy) with a total GPU training spend under $5, demonstrating that transformer-backbone custom-domain CV is accessible at pre-seed product development scale. The latency gate (sub-35ms) remains open, with float16 quantization and CoreML API optimization as the primary reduction candidates for Phase 1.
References
- Lv, W., et al. (2024). RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer. arXiv:2407.17140.
- Ultralytics. (2025). YOLO26: Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection. arXiv:2509.25164.
- Zhang, Y., et al. (2022). ByteTrack: Multi-Object Tracking by Associating Every Detection Box. arXiv:2110.06864. ECCV 2022.
- Aharon, N., et al. (2022). BoT-SORT: Robust Associations Multi-Pedestrian Tracking. arXiv:2206.14651.
- Ravi, N., et al. (2024). SAM 2: Segment Anything in Images and Videos. arXiv:2408.00714. Meta AI.
- Vasu, P. K. A., et al. (2023). FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization. arXiv:2303.14189. ICCV 2023.
- Apple Machine Learning Research. (2022). Deploying Transformers on the Apple Neural Engine. Apple Machine Learning Research Blog.